
Vigilar los registros y las métricas es un mal necesario para los administradores de clústeres. Los beneficios son claros: las métricas le ayudan a establecer objetivos de rendimiento razonables, mientras que el análisis de registros puede descubrir problemas que afectan a sus cargas de trabajo. La parte difícil, sin embargo, es conseguir que un montón de aplicaciones trabajen juntas en una solución de monitorización útil.El objetivo es proporcionar un mecanismo para el análisis log/metric de si el cluster está funcionando o no.
Además de las aplicaciones típicas relacionadas con K8s (etcd, flannel, balanceador de carga, master, y workers), existen aplicaciones adicionales para nuestros registros y selección de métricas, hablamos de Graylog y Prometheus
Graylog :
apache2: proxy inverso para la interfaz web de graylog
elasticsearch: base de datos para los logs
filebeat: reenvía los registros masters/slaves de K8s a graylog
graylog: proporciona un api para la recogida de registros y una interfaz para el análisis.
mongodb: base de datos para metadatos de graylog
Prometheus incluye lo siguiente:
grafana: interfaz web para cuadros de mando métricos
prometheus: colector métrico y base de datos de series cronológicas
telegraf: envía métricas del host a prometheus
Una vez desplegado Graylog podremos dar un vistazo a los logs que estamos recopilando. De forma predeterminada, la aplicación Filebeat enviará eventos de registro de syslog y de los logs de los contenedores a graylog (es decir, /var/log/*.log y /var/log/containers/*log)
Una vez que haysa iniciado sesión, diríjase a la pestaña Sources para obtener una descripción general de los registros recopilados
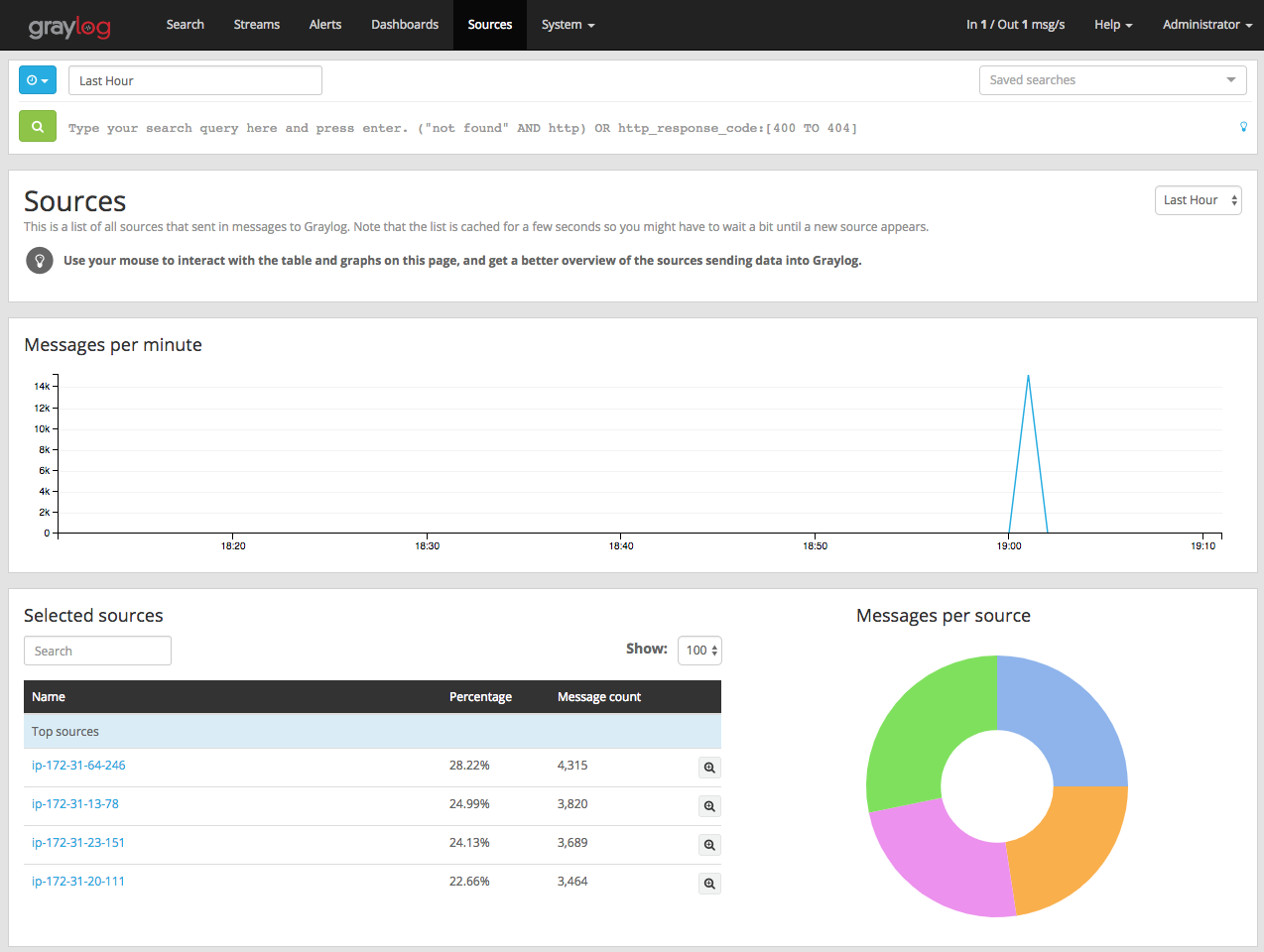
Desde aquí, es posible que desees configurar varios filtros o configurar el panel de control de Graylog para que te ayude a identificar los eventos que son más importantes
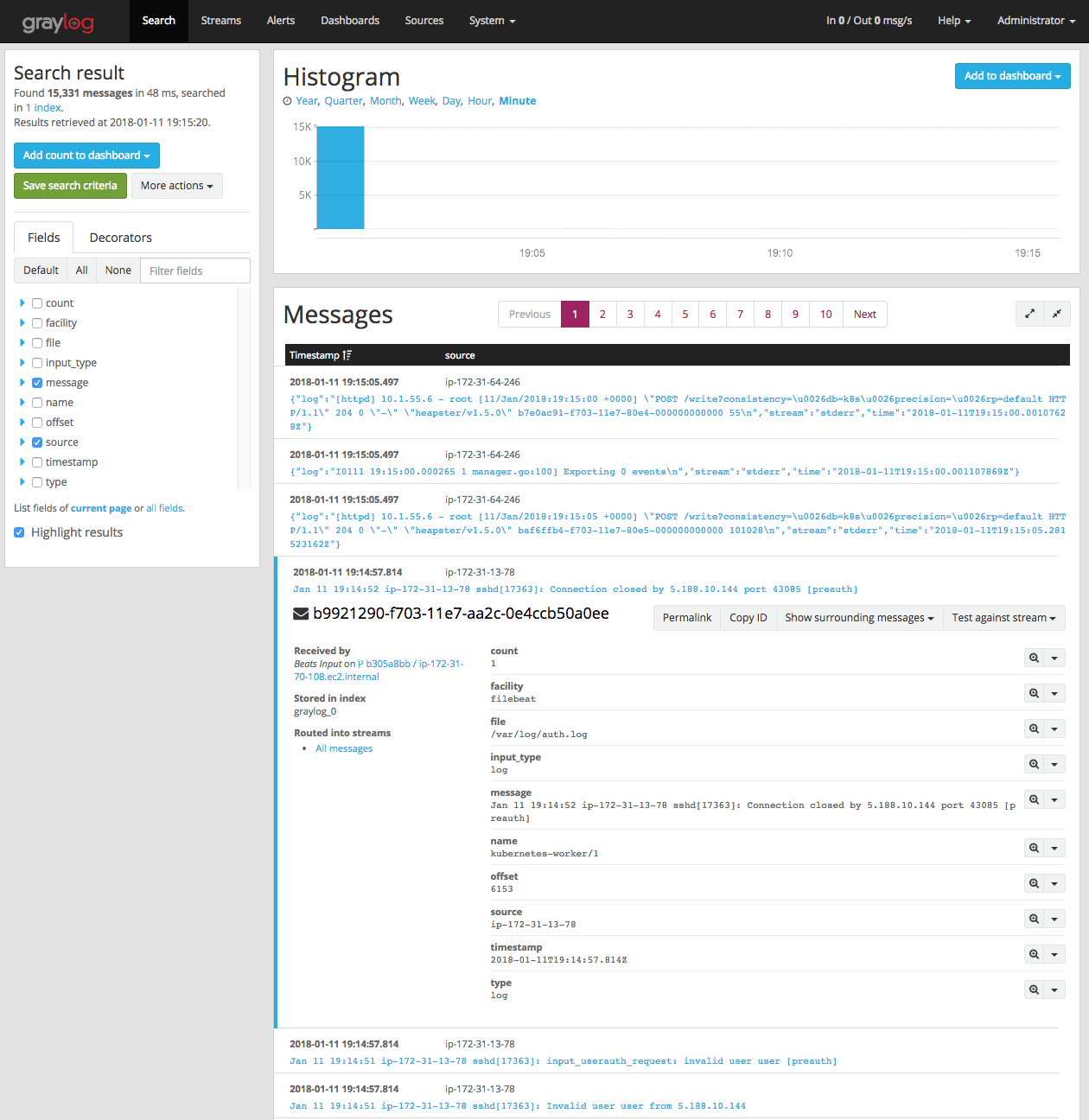
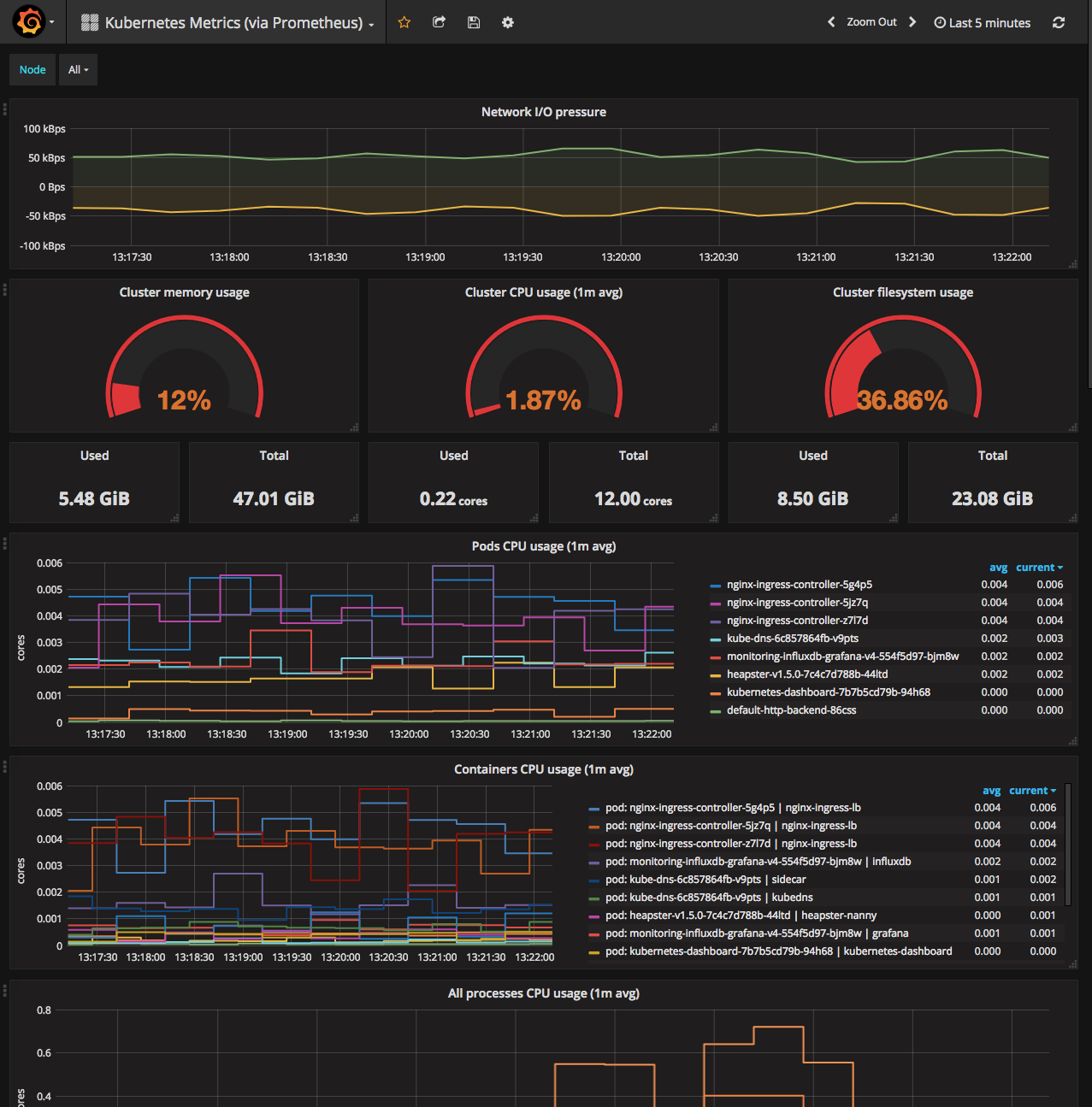
Explorando Métricas
Nuestro despliegue propone dos tipos de métricas a través de nuestros tableros de control de grafana: las métricas del sistema incluyen cosas como la utilización de cpu/memoria/disco del master de K8s cómo de los workers, las métricas de clúster incluyen datos a nivel de contenedor y de los endpoints K8s cAdvisor.
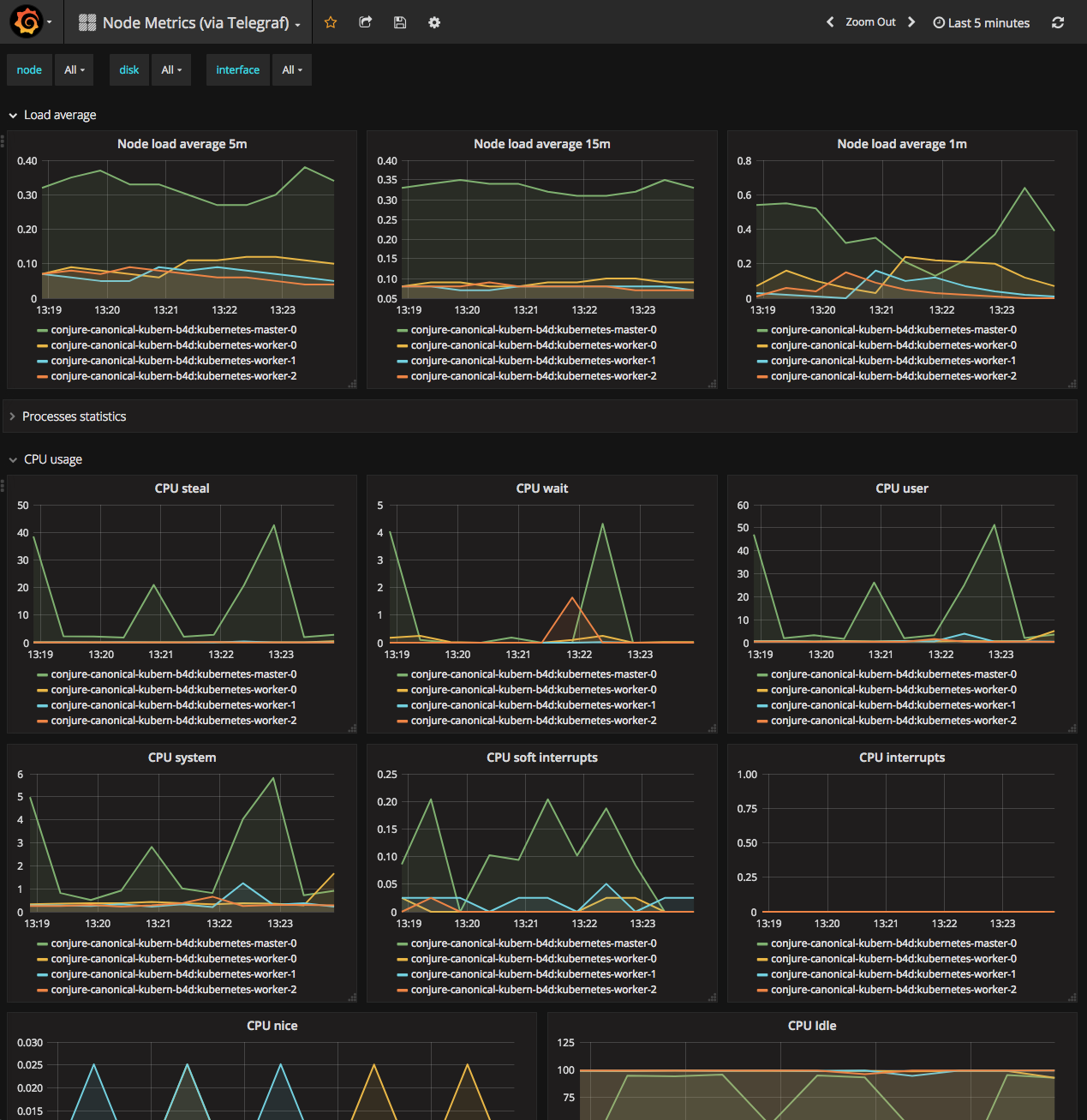
También podemos comprobar las métricas del sistema de nuestras máquinas host K8s (a través de Telegraf)
COMENTARIOS RECIENTES